Red Hat Ceph Storage est une plateforme de stockage logiciel permettant de provisionner en stockage des centaines de conteneurs et de machines virtuelles et de créer des plateformes cloud.
Ceph signifie céphalopode 🐙 🦑
Ceph
Concepts :
- reliable (fiable, résilient) : pas de SPOF, zéro downtime
- scalable (évolutif) : extensible facilement
- Auto-reparant : il gère les pannes de disque
Cas d’usages :
- Vitualisation (KVM, Proxmox, OpenStack, Kubernetes, …)
- Grands volumes de donnés
- Donnée “froides” (archivage)
- Partage de fichier multi serveurs (à la place de NFS ou lsyncd)
Principes de fonctionnement
Les objets
Sous Ceph, le terme objet désigne des fichiers, des ensembles de fichiers, BDD, … et tous ces fichiers sont découpés en objets.
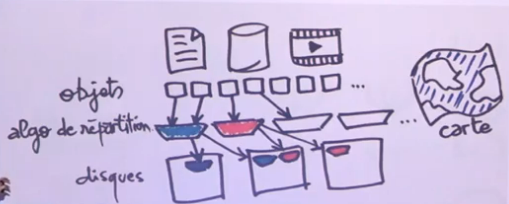
La problématique est de savoir comment stocker ces objets. Pour cela Ceph utilise un algorithme de répartition qui va se charger de répartir les objets sur les disques en fonction de la redondance voulue. Le tout géré par une “carte”.
En cas de pannes
Ceph est auto-réparant, dans le cas d’un RAID, on change le disque défaillant et il se recréé.
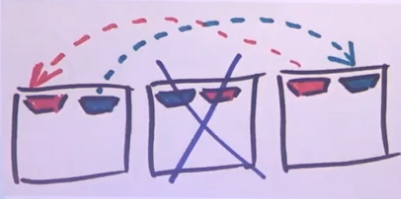
Dès qu’un disque tombe en panne, Ceph va le detecter et va copiera les données sur les autres disques afin de conserver la redondance voulue.
Ajout de disque
Ceph est souple lors de l’ajout de nouveaux disques.
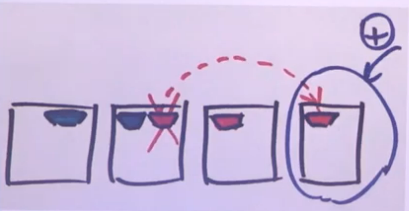
Lors de l’ajout d’un 4 ème disque et après l’avoir déclaré dans Ceph, il mettra directement à jour son schemas de repartion. L’augmentation de la capacité de stockage, la re-répartition des objets est dynamique et transparente.
Schéma Technique
Les fichiers sont transformés en objets et sont ensuite placés dans un pool oú ils seront stockés. Le pool sera ensuite découpé en PG (Placement Group)[Les bateaux] et selon la redondance, ils seront placés sur 1 ou plusieurs disques (les OSDs)
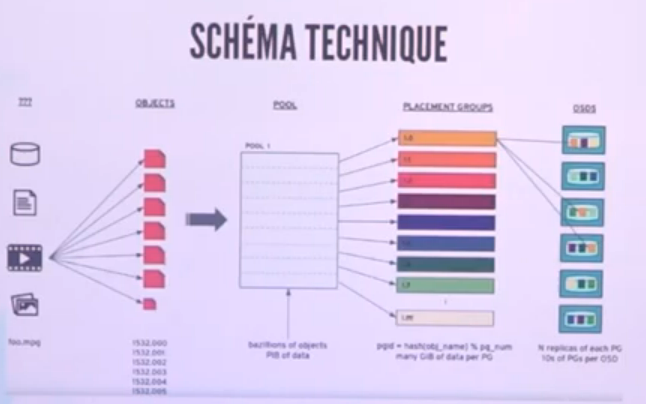
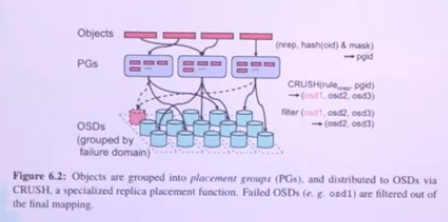
Composants de Ceph
OSDs - Object Storage Devices
OSD pour Object Storage Devices : disque comportant un CPU + RAM + Réseau
Chaque disque à son propre daemon, le daemon OSD ainsi que le daemon MON (Monitor, classiquement au nombre de 3 pour gérer l’état d’un cluster et transmettre la map pour avoir la vision d’ensemble). Il existe egalement un daemon MGR (manager, pour les stats)
Pour avoir du CephFS (pas obligatorie), il faut avoir des daemons MDS pour les meta datas
Optionnel aussi, demon RGW pour un accès en HTTP REST.
PG - Placement Group
PG pour Placement Group : 128 à 1024 PGs par pool. La redondance conseillée est de 3. Un PG est réparti sur 3 OSDs dont un OSD primaire, qui va piloter les écritures.
Pourquoi découper en PG ?

En fonction du nom de l’objet on peut savoir sur quel PG et OSD il se trouve

Pool
On peut avoir plusieurs pools par cluster avec chacun une utilisation différente : pool SSD, pool SATA, pool Vidéo, pool Mail, …
Redondance et réplication
Il existe 2 modes :
- Réplication : choix d’une redondance (3 conseillée)
- Erasure Coding : objets découpés en N+K de parité (un peu comme le RAID classique)
Accéder à Ceph
Il y a 3 modes :
- Block : RBD
- Filesystem : CephFS
- Objet : HTTP REST (compatible Amazon S3)
Clients
RADOS est l’ensemble des protocoles qui permettent au client d’accéder au cluster.

RADOS pour Reliable Autonomic Distriubuted Object Store est l’ensemble de logiciel fournissants les fonctionnalités pour Ceph comme la gestion de la distribution des objets et la santé du cluster
CRUSH pour Controlled Replication Under Scalable Hashing qui est l’algorithme pour localiser les objets à l’aide de la CRUSH Map et définie le regroupement d’objets en PG et le placement de ces dernier dans n OSD
Accès cluster Ceph
rbd map foo: /dev/rdb0 (dik accessible)
RBD via libvirt
librados pour C, C++, Python
CephFS : mount -t ceph (intégré dans le noyau Linux)
HTTP : curl, etc.
En pratique
Exemple d’un cluster de 3 machines avec 12 disques
# ceph status |
On a 4 disques par machine
# ceph osd tree |
Créer un pool nommé pool42 avec 512 PGs
# ceph sosd pool create pool42 512 |
Disque free de Ceph :
# ceph -df |
Sur le client, créer un volume block
# rbd create monVolume --size 1G --image-feature layering |
Sur le client, créer un volume CephFS
# mount.ceph 192.0.20.42:6789:/ /src/cephfs |
Cephfs gère les snapshots, la création se fait dans le répertoire /srv/cephfs avec la commande mkdir :
# cd /srv/cephfs |
Créer un snapshot de sous arboressence
# cd monSousRepertoire |
Documentation
https://www.redhat.com/fr/technologies/storage/ceph
https://www.youtube.com/watch?v=9VzZKGFfjGw